I want to share with you a performance issue that I had a couple of days ago.
Introduction
I implemented a sort of pricing rules for an e-commerce application with very high traffic, this involved extending some inherit column methods from a Ruby on Rails model in order to pass a context to the price, so it can be modified.
The feature was implemented, tested, and later deployed. But after a couple of hours, the BOFH sent me a message asking regarding some increased loading times in some sections of the web.
Big load average
We jumped into a call and we reviewed Datadog together, we couldn’t see what was causing the impact, but it was pretty clear the database load was increasing overtime. The load was in the CPU and the amount of queries we were doing, specifically SELECTs.
This coincidentally matched with Latin America waking up, that for us that means our highest peak of traffic, so we had to reformulate the averages in order to match the load.
Since the feature is touching prices, I had to invalidate a good amount of caches, and our cache storage and usage is big. Very big. Our theory was that, since we were regenerating caches, the load was normal, so we increased the amount of servers to support the new load and log off.
The next day
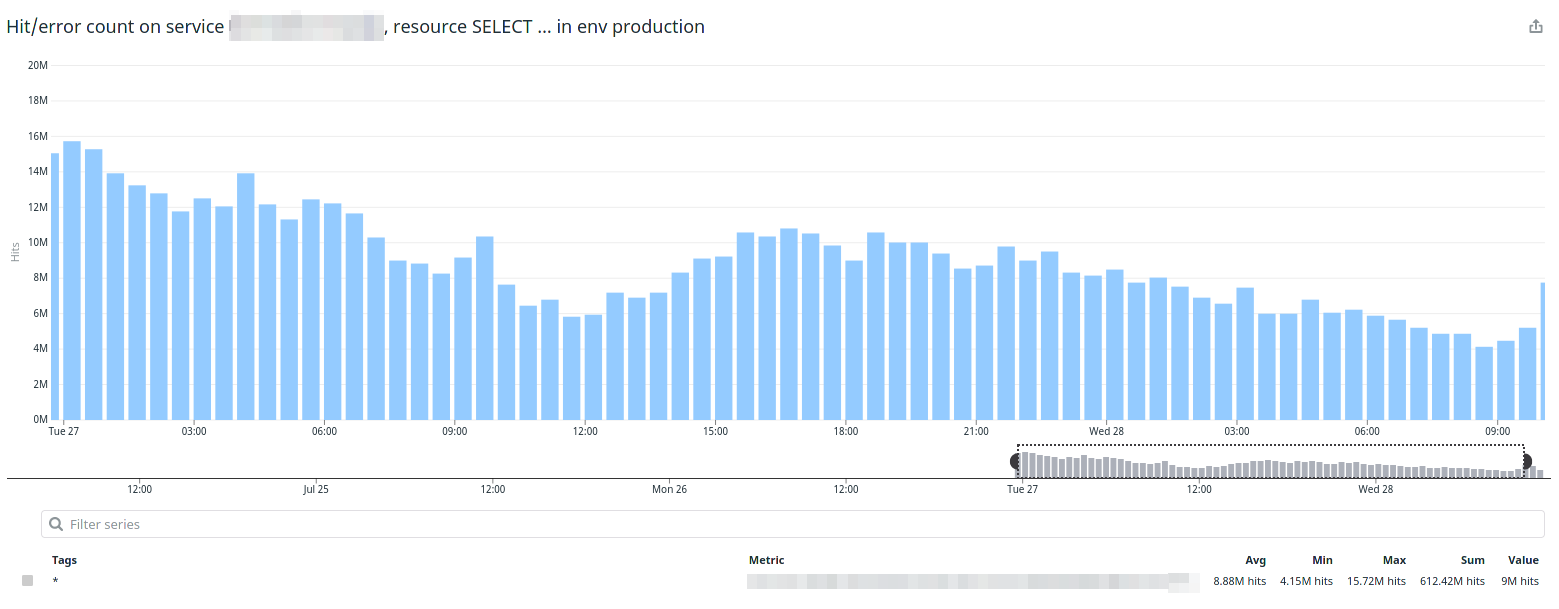
The next day we finally had some good data. We jumped into a call and visited Datadog again, and we saw that the feature I implemented was doing 20 million SELECTs per hour in average.
SELECT pricing_rules . *
FROM pricing_rules
WHERE pricing_rules . price = ?
AND pricing_rules . active = ?
AND pricing_rules . foo = ?
AND pricing_rules . bar = ?
LIMIT ?
20 million per hour sounds like a lot, and it is, but it’s something we usually handle.
I didn’t noticed that we actually call price 4 or 5 times each time we print a product. This is because we calculate the discount, the sale price, promotions, etc.
First try?
The solution was pretty simple, and I’m sure you’re thinking about it: use a cache to save the results from that query. Memcached is faster than SQL for this kind of caches, and we can relieve the database from this load easily. We already do that for Prices.
I went ahead and implemented the cache, it looked something like this:
class Price < ApplicationRecord
def mod_price(purchase_context = nil)
Rails::Cache.fetch(cache_key) do
self.pricing_rules.first_rule_that_apply # simplified
end
end
end
I did some testing locally and it worked like a charm, went ahead and released to staging, tested it out, looked good, and finally production.
After the deploy, we kept an eye on the metrics. And we waited. We waited a little more. And nothing.
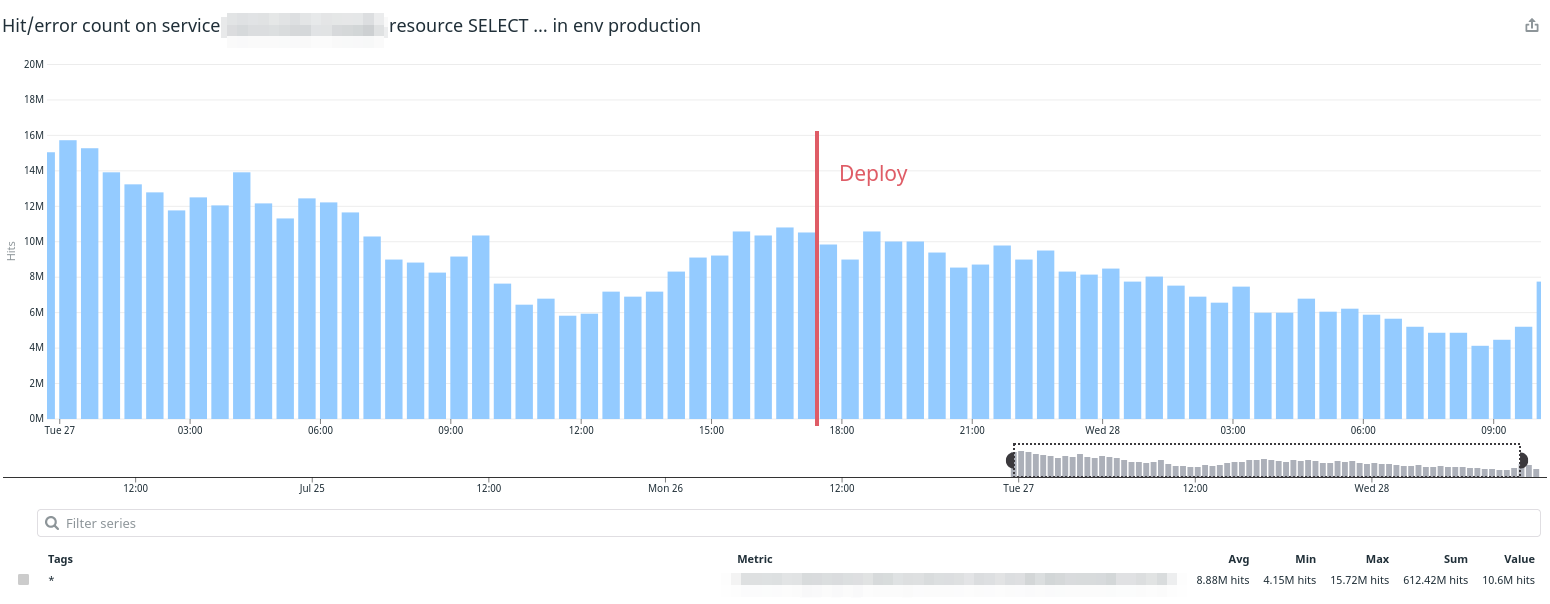
The decrease you see after the deploy is just traffic (Latin America going to sleep), the cache changed nothing. I debugged more: maybe I missed a call? It couldn’t be since this method is called in every implementation by a top level method. Is the cache being written slower than expected? Could be.
So I wrote a script to generated 18 million cache keys. I ran the script, took around 30 minutes to complete and nothing again. We were doing the same amount of calls.
I kept communication with Infrastructure and even though it wasn’t solved, we were okay until next day.
Wait a second…
I took a walk with the dogs and then it hit me: does Memcached allow nil values? I know, based on my local testing, it does. But maybe I was not using Memcached for development, or had a different configuration.
So I came back, and after dinner and test it out in the production console directly.
> Rails.env
=> "production"
> Rails.logger.level = Logger::DEBUG
=> 0
> def my_method
Rails::Cache.fetch('my_random_key') do
User.last
nil
end
end
> my_method
# Cache read: my_random_key
# Dalli::Server#connect xx.xx.xx.xx:xxxx
# Cache generate: my_random_key
# User Load SELECT `users`.* FROM `users` ORDER BY `users`.`id` DESC LIMIT 1
# Cache write: my_random_key
=> nil
> my_method
# Cache read: my_random_key
# Cache generate: my_random_key
# User Load SELECT `users`.* FROM `users` ORDER BY `users`.`id` DESC LIMIT 1
# Cache write: my_random_key
=> nil
Oh no. It doesn’t save nil values. And since we don’t have a record in the database, the method will always run the query because the cache has nothing.
The solution
So what can I use? An empty string works but I don’t like it at all. I read about using a boolean, but I’m not a fan either. Let’s use a Struct!
NullData = Struct.new(nil)
class Price < ApplicationRecord
def mod_price(purchase_context = nil)
Rails::Cache.fetch(cache_key) do
self.pricing_rules.first_rule_that_apply || NullData.new
end
end
end
But first let’s test it out:
> NullData = Struct.new(nil)
=> NullData
> def my_method
Rails::Cache.fetch('my_random_key') do
User.last
NullData.new
end
end
> my_method
# Cache read: my_random_key
# Cache generate: my_random_key
# User Load SELECT `users`.* FROM `users` ORDER BY `users`.`id` DESC LIMIT 1
# Cache write: my_random_key
=> #<struct NullData>
> my_method
# Cache read: my_random_key
# Cache fetch_hit: my_random_key
=> #<struct NullData>
I deployed this to production and the magic happened.
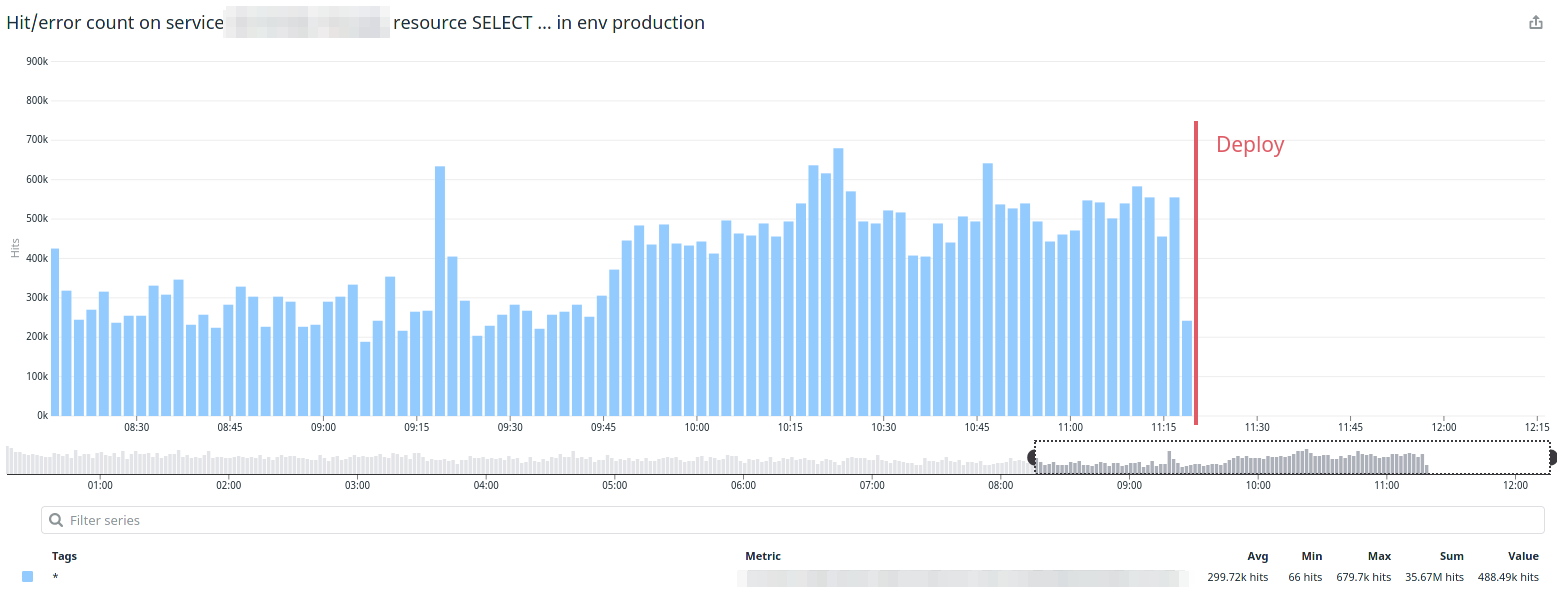
What I learned
So I learned that:
-
I need to have Memcached configured as production to avoid these kind of errors.
-
To read the documentation, specifically Dalli and Memcached.
-
Caching is a pain in the ass, but when it works, it works like a charm.
-
To test better and think about cache every time, specially in an application of this size.
Thanks for reading, until next time!










